1. 组合/非组合型
1.1 非组合型(unpacked)
数组中的成员之间存储数据都是互相独立的。如
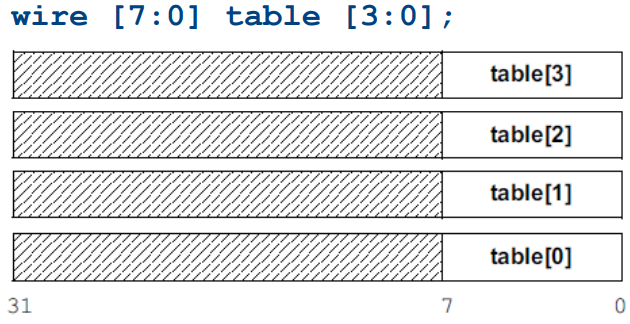
1.2 组合型(packed)
组合型(packed)除了可以运用的数组声明,也可以用来定义结构体的存储方式:
typedef struct packed {
logic [ 7:0]crc;
1ogic [63:0]data ;//此处两个数字为连续存放
}data _word;
data word [7:0]darray;
// 1-D packed array of
//packed structures
组合型数组和其数组片段也可以灵活选择,用来拷贝和赋值等组
logic [3:0][7:0]data; //2-D packed array
wire [31:0] out = data;//whole array
wire sign = data[3][7]; //bit-select
wire [3:0] nib = data [01][3:0]; //part-select
byte high byte;
assign high byte = data[31] ; //8-bit slice
logic [15:0] word;
assign word = data[1:0]; // 2slices
四值逻辑数组存放空间较二值逻辑数组所需空间翻倍
1.3 差别
组合型数组的维度声明在数组名左边,高位同样在左,低维在右
1.4 数组初始化
组合型(packed)数组初始化时,同向量初始化一致:
非组合型(unpacked)数组初始化时,则需要通过’{来对数组的每一个维度进行赋值。
int d [0:1][0:3] = '{ ' { 7,3,0,5}, '{2,0,1,6} };
//d[0][01 = 7
//d[0][1] = 3
//d[0][2] = 0
//d[0][3] = 5
//d[1][0] = 2
//d[1][1] = 0
//d[1][2] = 1
//d[1][3] = 6
1.5 赋值
非组合型数组在初始化时,也可以类似结构体初始化,通过′{}和default关键词即可以完成
非组合型数组的数据成员或者数组本身均可以为其赋值
赋值方法
2. 拷贝
2.1 组合型与组合型
对于组合型数组,由于数组会被视为向量,因此当赋值左右两侧操作数的大小和维度不相同时,也可以做赋值。
如果当尺寸不相同时,则会通过截取或者扩展右侧操作数的方式来对左侧操作数赋值。
bit [1:0][15:0]a; //32 bit 2-state vector
logic [3:0][7:0] b; //32 bit 4-state vector logic [15:0] c; //16 bit 4-state vector
logic [39:0] d; //40 bit 4-state vector
b = a; //assign 32-bit array to 32-bit array
c = a; //upper 16 bits will be truncated,高16位将被舍去
d = a; //upper 8 bits wil1 be zero filled,高八位将被赋0
2.2 非组合型与非组合型
对于非组合型数组,在发生数组间拷贝时,则要求做左右两侧操作数的维度和大小必须严格一致。
logic [31:0] a [2:0][9:0];
logic [O: 31] b [1:3][1:10];
a = b; //assign unpacked array to unpacked array
2.3 组合型与非组合型
非组合型数组无法直接赋值给组合型数组,同样地,组合型数组也无法直接赋值给非组合型数组。
2.4 数组的索引——foreach循环结构
SV添加foreach循环来对一维或者多维数组进行循环索引,
而不
需要指定该数组的维度大小。
int sum [1:8][1:3];
foreach ( sum[i,j])
sum[i][j] = i +j; //initialize array
foreach循环结构中的变量无需声明。
foreach循环结构中的变量是只读的,其作用域只在此循环结构中。
3. 动态数组
3.1 声明方式
动态数组在声明时需要使用[],这表示不会在编译时为其制定尺寸,而是在仿真运行时来确定。
动态数组一开始为空,而需要使用new[]来为其分配空间
3.2 使用实例

4. 队列
4.1 声明方式
通过[$]来声明队列,队列的索引值从0到$。
4.2 使用实例


5. 关联数组
SV引入了关联数组,可以用来存放散列的数据成员。散列的索引类型除了为整形以外还可以为字符串或者其它类型,而散列存储的数据成员也可以为任意类型。
5.1 使用实例
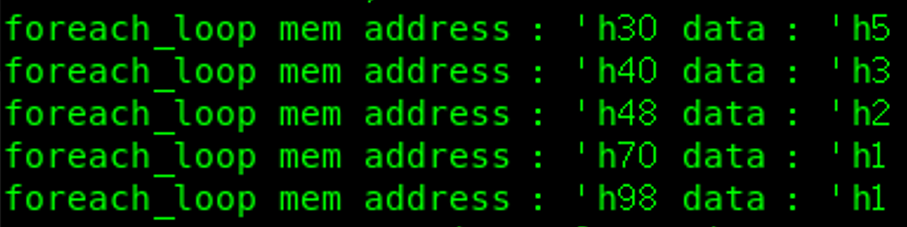
module tb;
initial begin
bit [31:0] mem [int unsigned];
int unsigned data, addr;
repeat(5)begin
std::randomize(addr,data) with {addr[31:8] == 0; addr[1:0] == 0; data inside {[1:10]}; };
$display("address : 'h%0x, data : 'h%0x", addr, data);
mem[addr] = data;
foreach(mem[idx])
$display("mem adress : 'h'%0x, data : 'h%0x", idx, mem[idx]);
end
end
endmodule
仿真结果:


6. 数组的方法
6.1 数组缩减
基本的数组缩减方法是把一个数组缩减成一个值。
最常用的缩减方法是sum,它对数组中的所有元素求和。
byte b[$] = {2,3,4,5};
int W;
w = b.sum(); // 14=2+3+4+5
w = b.product(); // 120 = 2 *3*4*5
W = b.and(); // 0000 0000 = 2&3&4& 5
其它的数组缩减方法还有product(积), and(与), or(或)和xor(异或)。
6.2 数组定位
对于非合并数组,可以使用数组定位方法,其返回值将是一个队
列而非一个数据成员。
int f[6] = '{1,6,2,6,8,6}; // Fixed-size array
int d[] = '{2,4,6,8,10}; // Dynamic array
int q[$] = {1,3,5,7}, // Queue ;
tq[$] ; // Temporary queue for result
tq = q.min(); // {1}
tq = d.max(); // {10}
tq = f.unique(); // {1,6,2,8}
使用foreach也可以实现数组的搜索,不过使用find…with则在查找满足条件的数据成员时,更为方便。

6.3 数组排序
可以通过排序方法改变数组中元素的顺序,可以对它们进行正向、逆向或者乱序的排列。
int a [] = {9,1,8,3,4,4};
d. reverse(); //{4,4,3,8,1,9}
d.sort(); //{1,3,4,4,8,9}
d.rsort(); //{9,8,4,4,3,1}
d.shuffle(); //{9,4,3,8,1,4}
7. 问答题
1.链表和SV中的哪些数组类型(定长数组、动态数组、队列、关联数组)相似,相似的特性有哪些?
链表数据在实际存储时,所在的内存地址并不连续,数据随机分布在内存中的各个位置,这种存储结构成为练市存储。链式存储生成的表成为链表。但为了能够保持数据元素之间的顺序关系,每个数据元素在存储的同时,都要配备一个指针,指向它的直接后继元素,每一个数据元素都指向下一个数据元素,这些由指针相互连接的数据,就具有了线性的关联。
删除链表的元素只需要把前节点的指针域,越过要删除的节点直接指向下一个节点,然后释放被删除节点的空间。若不释放,被删节点成为野指针,造成内存泄露。
添加链表的元素时需要先确定要添加的位置,然后把前节点的指针域指向自身,再将自身的指针域指向下一个节点即可。
链表与数组的区别(C语言):
应用场景方面:数组必须事先定义长度(元素个数),并分配固定大小的空间,不能适应数据动态增减的情况,不能适应数据动态增减的情况。相反,链表可以动态地进行内存分配,可以适应数据动态增减的情况,且可以方便地插入、删除数据项。
内存方面:数组从栈中分配空间,所有关于内存的申请开辟或者析构释放都由系统完成,方便快速,但是自由度小。链表从堆中分配空间,用多少,就开辟多少内存,自由度大,内存的申请管理较麻烦。
操作效率方面:在插入或者删除数组中的元素时,其后的所有元素都要被移动。而在链表中插入或者删除某节点时,只需修改指针即可,不需要移动节点。 因此插入删除元素,链表的效率由于数组。但在访问效率方面,由于数组的内存是连续的,则可以直接使用下标访问数组电的某个元素。链表的内存是不连续的,要访问链表中的某个节点,必须从头节点开始查找。因此,链表的访问效率不如数组。
回到SystemVerilog,链表在增删元素操作上与队列相似,可以在数据中任何地方添加或者删除元素。(但值得注意的是,队列同时又具有数组的优点,可以通过索引实现对任一元素的访问,这一点优于链表。) 链表在动态分配内存上同动态数组类似链表能够动态地进行内存分配,这一点同动态数组类似。使用动态数组可以在仿真时分配空间或调整宽度。动态数组在声明时使用空的下标[],数组的宽度不在编译时给出,而在程序运行时再指定,调用new[]操作符来分配空间,同时在方括号中传递数组宽度。
SystemVerilog虽然提供了链表数据结构,但是应该避免使用它,因为SystemVerilog提供的队列更加高效易用。



